

Das Problem
Wir haben eine Reihe von Messpunkten  .
.
Um uns einen Überblick zu verschaffen, zeichnen wir sie in einem Diagramm auf, und sie scheinen längs einer Geraden zu liegen, wenn auch nicht exakt. Wir vermuten einen linearen Zusammenhang, d.h. dass die Messwerte durch eine einfache Funktion dargestellt werden kann, und dass Abweichungen durch Messfehler hervorgerufen wurden.

Wir suchen nun eine lineare Funktion  , so dass für alle
, so dass für alle  gilt:
gilt:  , und dies in einer noch zu definierenden optimalen Weise. Mit einer linearen Funktion meinen wir dabei, dass von der Gestalt
, und dies in einer noch zu definierenden optimalen Weise. Mit einer linearen Funktion meinen wir dabei, dass von der Gestalt  ist mit zwei Zahlen
ist mit zwei Zahlen  und
und  . Diese Gleichung haben wir in der Schule als Geradengleichung kennengelernt. (Mathematisch korrekt spricht man von einer affinen Funktion, denn für lineare Funktionen gilt
. Diese Gleichung haben wir in der Schule als Geradengleichung kennengelernt. (Mathematisch korrekt spricht man von einer affinen Funktion, denn für lineare Funktionen gilt  . Darauf kommen wir noch zurück).
. Darauf kommen wir noch zurück).
Im Allgemeinen wird nicht durch alle gegebenen Punkte gehen, wenn diese nicht wirklich auf einer Linie aufgereiht sind.
Der einfachste Fall: 2 Punkte
Wenn wir nur zwei Punkte  und
und  haben, so finden wir natürlich eine Gerade durch diese Punkte. Die Rechnung ist einfach: Wir berechnen durch
haben, so finden wir natürlich eine Gerade durch diese Punkte. Die Rechnung ist einfach: Wir berechnen durch
![\[m = \frac{y_2 - y_1}{x_2 - x_1}\]](https://www.infaktum.de/wp-content/ql-cache/quicklatex.com-e88885de90f118bc205cdeaeab20d55f_l3.png "Rendered by QuickLaTeX.com")
und erhalten so die Steigung der Geraden .
Den Wert für erhalten wir dann durch Einsetzen von in die Gleichung  , also
, also
![\[b = y_1 - \frac{y_2 - y_1}{x_2 - x_1} x_1 = y_1 - m x_1\]](https://www.infaktum.de/wp-content/ql-cache/quicklatex.com-0ea3436832a3caebbff00338c33fdc41_l3.png "Rendered by QuickLaTeX.com")
Implementierung in Python
Mit Hilfe von NumPy können wir die Berechnung der Geraden „direkt hinschreiben“.
import numpy as np
import matplotlib.pyplot as plt
def g(x,y):
'''Berechnet die Gerade durch zwei Punkte'''
m = (y[1] - y[0]) / (x[1] - x[0])
b = y[0] - m * x[0]
return lambda x: m * x + b
# Test für zwei Punkte
xp = [1,5]
yp = [3,8]
x = np.arange(0,8)
plt.ylim(0,10)
plt.xlabel(' ')
plt.ylabel('
')
plt.ylabel(' ')
plt.scatter(xp,yp)
plt.plot(x,g(xp,yp)(x))
plt.show()
')
plt.scatter(xp,yp)
plt.plot(x,g(xp,yp)(x))
plt.show()
Die Lineare Regression
Was macht man nun bei mehr als zwei Punkten, die nicht exakt auf einer Geraden liegen? Wie finden wir eine Ausgleichsgerade, die „möglichst nahe“ an allen diesen Punkten liegt? Dann könnten wir die Gerade als Funktion betrachten, die diese Wertepaare erzeugt, wobei die Abweichungen möglichst klein sind. Dabei wird es eher die Regel sein, dass die Gerade nicht einmal durch einen einzigen dieser Punkte läuft. Ausgehend von dieser Gerade könnten wir dann Werte zwischen den gegebenen Punkten vorhersagen (interpolieren), oder die Werte von Punkten, die links oder rechts von unserem Messbereich liegen (extrapolieren).
Dazu müssen wir erst einmal überlegen, was es bedeutet, dass die Gerade möglichst nahe an allen Punkten liegt und in diesem Sinne optimal ist. Der folgende Ansatz hat sich bewährt:
Zu einer gegebenen Funktion  definiert man den Abstand
definiert man den Abstand  der Wertepaare zu dieser Funktion als
der Wertepaare zu dieser Funktion als
![\[D := \sum_{k=1}^N (F(x_k) - y_k)^2.\]](https://www.infaktum.de/wp-content/ql-cache/quicklatex.com-a806d85a4f5c4296f6fc1f0e750178ff_l3.png "Rendered by QuickLaTeX.com")
Es wird also summiert über die Quadrate der Differenzen der Funktionswerte und der tatsächlichen Werte.
Warum macht diese Funktion Sinn? Sie bestimmt zu jedem Wertepaar das Quadrat der Abweichung  . Dieses Quadrat ist positiv, und dadurch können sich negative und positive Abweichungen nicht aufheben. Zudem werden größere Abweichung stärker gewichtet. Wir bilden die Summe über alle gegebenen Punkte, dadurch werden alle Wertepaare gleich berücksichtigt. Diese Fehlerquadratsumme ist ein geeignetes Maß, um Funktionen zu bewerten. Dabei spielt es keine Rolle, ob die Funktion ein Polynom ist oder irgendeine andere Form hat.
. Dieses Quadrat ist positiv, und dadurch können sich negative und positive Abweichungen nicht aufheben. Zudem werden größere Abweichung stärker gewichtet. Wir bilden die Summe über alle gegebenen Punkte, dadurch werden alle Wertepaare gleich berücksichtigt. Diese Fehlerquadratsumme ist ein geeignetes Maß, um Funktionen zu bewerten. Dabei spielt es keine Rolle, ob die Funktion ein Polynom ist oder irgendeine andere Form hat.
Gesucht ist nun eine Funktion , die diese Fehlerquadratsumme minimiert. Bei der Linearen Regression wird dabei eine lineare Funktion gesucht, d.h. eine Funktion der Gestalt
![\[F(x) = mx + b.\]](https://www.infaktum.de/wp-content/ql-cache/quicklatex.com-3e6f17866ccdfd55f4c95a2a30dcd133_l3.png "Rendered by QuickLaTeX.com")
Der Ansatz wird die Methode der kleinsten Quadrate genannt.
Wie wir gesehen haben, gibt es bei zwei Wertepaaren ( ) genau eine lineare Funktion, die durch die beiden Punkte geht und die damit zu 0 macht. Für
) genau eine lineare Funktion, die durch die beiden Punkte geht und die damit zu 0 macht. Für  wird es im allgemeinen keine Gerade geben, die durch alle Punkte geht, aber es gibt genau eine Funktion , die minimiert. Dies sieht man wie folgt:
wird es im allgemeinen keine Gerade geben, die durch alle Punkte geht, aber es gibt genau eine Funktion , die minimiert. Dies sieht man wie folgt:
Für Funktionen  ist die Fehlerquadratsumme
ist die Fehlerquadratsumme
![\[D(F) = D(m,b) = \sum_{k=1}^N (F(x_k) - y_k)^2 = \sum_{k=1}^N (mx_k + b - y_k)^2\]](https://www.infaktum.de/wp-content/ql-cache/quicklatex.com-933f87f686c99866f2f4745ca766c064_l3.png "Rendered by QuickLaTeX.com")
eine Funktion der beiden Parameter
und . Gesucht sind zwei Zahlen  , so dass
, so dass  minimal ist. Dort muss
minimal ist. Dort muss ![\[\nabla D(m,b) = 0\]](https://www.infaktum.de/wp-content/ql-cache/quicklatex.com-2f5eee9022e51bac2265141e9024871a_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{\partial D}{\partial m} (m,b) = 0, \frac{\partial D}{\partial b} (m,b)= 0\]](https://www.infaktum.de/wp-content/ql-cache/quicklatex.com-418d45ce16787cc3ffd8ae16671c7490_l3.png "Rendered by QuickLaTeX.com")
Dies führt zu dem linearen Gleichungssystem (oder besser dem affinen Gleichungssystem)
(1) 
und nach einigen Umformungen (und Streichen der 2)
(2) 
Dieses Gleichungssystem hat die Form
(3) 
und besitzt die eindeutige Lösung
(4) 
Dieses Verfahren lässt sich leicht implementieren. Dazu berechnet man zunächst aus den gegebenen Wertepaaren
![\[a_1 = \sum x_k^2, b_1 = \sum x_k, c_1 = \sum x_k y_k, \;a_2 = \sum x_k, b_2 = N, c_2= \sum y_k\]](https://www.infaktum.de/wp-content/ql-cache/quicklatex.com-338a65819a06bb9143144fb209aff89e_l3.png "Rendered by QuickLaTeX.com")
und bestimmt dann
und gemäß der angegebenen Gleichung.
Implementierung der linearen Regression
Wieder können wir mit Hilfe von NumPy die Formeln direkt abschreiben.
def koeff(x,y):
"""
Berechnung der Koeffizienten des Gleichungssystems
a1*m + b1*b = c1
a2*m + b2*b = c2
"""
sum_x = np.sum(x)
sum_y = np.sum(y)
sum_xx = np.sum(x * x)
sum_xy = np.sum(x * y)
N = x.shape[0]
return sum_xx, sum_x, sum_xy, sum_x, N, sum_y
def lin_reg(x,y):
"""Einfache Implementierung der linearen Regression"""
a1, b1, c1, a2, b2, c2 = koeff(x,y)
# Lösung des Gleichungssystems
b = (a2 * c1 - a1 * c2) / (a2 * b1 - a1 * b2)
m = (c1 - b1 * b) / a1
return (m,b)
def D(x,y,,f):
"""Die Distanzfunktion berechnet die Fehlerquadratsumme"""
return np.sum((f(x) - y)**2)Wir implementieren noch einige Hilfsfunktionen für Polynome
def poly_gen(a:np.ndarray):
"""Erzeugt ein Polynom mit den Koefizienten aus a."""
return (lambda x: np.sum([a[k] * x**k for k in range(a.shape[0])]))
def poly_text(cff):
"""Ausgabe des Polynoms in Text-Form. """
comp = []
text = "g(x) = "
for n,a in enumerate(cff):
c = "{:.3f}".format(a)
if n > 0:
c += "x"
if n > 1:
c += "^" + str(n)
comp.append(c)
comp.reverse()
for c in comp:
text += c + " + "
text = text[:-3]
return text
def poly_plot(x,y,a):
plt.xlim(0,10)
plt.ylim(min(0,np.min(y) - 3),np.max(y)+3)
plt.xlabel('')
plt.ylabel('')
plt.title(poly_text(a))
plt.grid(True)
plt.scatter(x,y,color='red')
P = poly_gen(a)
xp = np.linspace(-1,np.max(x)+2,100)
yp = [P(x) for x in xp]
plt.plot(xp,yp) Wir zeigen die Berechnung des Gradienten am (einfachsten) Beispiel mit drei Punkten
x,y = np.array([1,3,6]),np.array([5,10,13])
plt.scatter(x,y,color='red')
plt.show()
g = np.flip(np.array(lin_reg(x,y)))
poly_plot(x,y,g)
plt.show()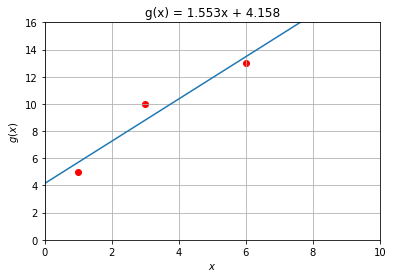
Ein etwas größeres Beispiel
Wir berechnen einige Punkte für die Funktion  und „verrauschen“ die Messergebnisse. Unsere Ausgleichgerade sollte dann ähnliche Koeffizienten wie haben.
und „verrauschen“ die Messergebnisse. Unsere Ausgleichgerade sollte dann ähnliche Koeffizienten wie haben.
N=20
x = np.linspace(1,10,N) + np.random.normal(0,1,N)
y = 3 * x + 5 + np.random.normal(0,3,N)
g = np.flip(np.array(lin_reg(x,y)))
poly_plot(x,y,g)
plt.show()
Zur Geschichte des Verfahrens
Das Verfahren wurde Anfang des 19. Jahrhundert von Carl Friedrich Gauß entwickelt. Die wissenschaftliche Welt stand damals vor der Herausforderung, dass der gerade entdeckte Planetoid Ceres hinter der Sonne verschwand, und nun anhand weniger Messdaten wiedergefunden werden musste. Gauß konnte mit seiner neuen Methode die Bahn so gut vorausberechnen, dass die Astronomen wussten, wo sie zu suchen hatten und Ceres sehr schnell wiederentdeckt werden konnte. (s. Methode der kleinsten Quadrate bei Wikipedia.)
